S’adapter au profil de l’apprenant, à ses préférences, ses connaissances déjà acquises, son rythme d’apprentissage… en résumé à ce qu’il est intrinsèquement, c’est à dire unique. Le psychologue américain Skinner en rêvait, L’intelligence artificielle et la révolution techno-pédagogique l’ont fait ! L’adaptive learning ou « apprentissage adapté » conjugue désormais au présent et sans doute plus finement encore dans un futur proche l’analyse des données de l’apprenant et de ses pairs pour lui proposer, via des algorithmes, une pédagogie et des parcours de formation sur-mesure.
L’objectif ? Maximiser l’efficacité de la formation et l’engagement de l’apprenant en combinant big data, sciences cognitives, ingénierie pédagogique et accompagnement tutoral. Tour d’horizon de ce que l’on nous annonce comme la prochaine révolution apprenante.
1.
TITRE
Je ne suis pas un numéro ! En revanche, force est de constater que l’on m’a réduite en équation depuis quelques temps déjà. Démonstration…
Connexion sur mon compte Amazon. En tête de gondole numérique, une recommandation pour deux ouvrages sur les neurosciences de l’éducation, suivi d’un ouvrage sur l’architecture et d’un roman policier. Je ne vous connais pas Jeff Bezos mais il semble que vous, en revanche, ayez cerné mes centres d’intérêt. Analyse de ce que vos algorithmes, Monsieur, ont choisi de me présenter :
- les neurosciences de l’éducation : acheter trois à quatre fois par an des ouvrages sur ce thème laisse des traces ; mes traces de lecture professionnelle ;
- l’architecture : j’ai travaillé sur les styles d’architecture il y a deux mois environ ; ça ne vous a pas échappé ;
- le roman policier : le dernier roman que j’ai acheté, sur recommandation humaine cette fois (mes amis connaissent eux aussi mes goûts littéraires), procède a priori d’une intrigue apparentée à celui que vous me poussez en page d’accueil. D’ailleurs, vous en voulez pour preuve : ceux qui ont acheté le même roman que moi ont aussi acheté celui que vous me proposez !
Et en scrollant je m’aperçois, Monsieur Bezos, que vous ne vous en tenez pas à mes lectures, vous avez décortiqué mes achats de consommables photo et informatique…
Derrière cette liste à la Prévert qui compose la page d’accueil personnalisée de mon compte, une analyse fine du nombre de mes clics et du temps passé sur tel ou tel ouvrage, de mon parcours de navigation sur le site, de mes achats sur une période donnée, de mes choix de livraison. Tout ce qui a pu être capté comme comportement l’a été. Et au vu des traces numériques que j’ai laissé sur votre parcours client, vous m’avez même doté d’un profil puisque vous m’encouragez à consommer comme tel ou tel qui a pris la peine de noter ou commenter ses achats et dont le parcours client doit ressembler au mien.
Et en plus vous vous payez le luxe, Monsieur, de m’appeler par mon prénom !

Et si l’on procédait ainsi en formation digitale, ça donnerait quoi ?
Les LMS aujourd’hui sont capables de pister les comportements d’un apprenant et de fournir une masse de données individuelles et collectives impressionnante, le plus souvent inexploitée.
Les big data sont la base de l’adaptive learning. Mais encore faut-il en décrypter le sens grâce aux learning analytics. L’interprétation pertinente de ces données alimente un moteur d’intelligence artificielle. De quoi créer des cohortes d’apprenants de profil similaire. Les comportements de l’apprenant sont modélisés grâce à l’observation de chacune de ses actions sur l’interface mais aussi de son temps passé sur chacun des contenus, de ses résultats aux évaluations formatives et sommatives. Ils permettent de tracer le chemin individuel d’acquisition de connaissances le plus efficace. Les résultats aux tests en ligne constituent de précieux indicateurs pour ajuster le rythme de déblocage et le niveau des contenus. Ils alimentent le moteur de recommandation qui va sélectionner les contenus adaptés à la progression de chacun.
Les sciences cognitives et les neurosciences de l’éducation viennent en appui de la programmation des algorithmes chargés d’analyser en temps réel les comportements et d’orienter la formation vers de la vidéo plutôt que du texte, de ralentir le rythme en cas de fatigue de l’apprenant… Car oui, il est possible d‘identifier une baisse d’attention de l’apprenant, en analysant son nombre de clics, le temps de connexion et de la fréquence de déconnexion.
Marie Sacksick, doctorante à Paris 8 et data scientist chez Domoscio (l’un des leaders européen sur l’adaptive learning) expliquait récemment dans une interview que les sciences cognitives constituent un garde fou à des recommandations illogiques que pourrait proposer l’algorithme.
Pour résumer, l’adaptive learning est une combinaison savante de données d’apprenants, d’algorithmes de recommandations, de contenus finement découpés et qualifiés, de parcours de formation différenciés (on peut imaginer une cartographie de savoirs et savoir-faire reliés entre eux par de multiples chemins pour arriver à destination : l’acquisition de compétences définies) et réfléchis sur la base des apports des neurosciences de l’éducation. Mais ne manque-t-il pas un élément majeur ? Quid du formateur dans l’adaptive learning ? Moins détenteur de savoir que mentor, son rôle évolue mais reste fondamental, comme nous le verrons.
Est-on si loin de la machine à apprendre de Skinner ?
2.
De l’enseignement PROGRAMMÉ à l’enseignement ADAPTÉ :
où es-tu Skinner ?
Rappelez-vous… Nous sommes dans les années 50. Pavlov et son chien ont déjà marqué de leur empreinte le début du XXe siècle. Skinner oppose alors au conditionnement pavlovien, un conditionnement opérant basé sur un système d’apprentissage par la machine, alternant récompenses (renforcement positif) et punitions (renforcement négatif) en fonction des résultats du sujet (des souris au départ, puis des enfants ensuite). Rétrograde penserez-vous ? Pas tant que ça au regard des avancées techno-pédagogiques de l’époque.

Les travaux de Skinner ont mis en évidence quelques grandes conditions d’efficience d’un apprentissage (vous constaterez que si la mise en œuvre peut paraître quelque peu manichéenne et obsolète, la plupart de ces postulats d’efficience restent d’actualité) :
- l’apprenant doit être actif dans la construction de ses connaissances ;
- les niveaux de difficultés doivent être découpés finement pour ne pas décourager les plus faibles ;
- la progression doit être graduelle ;
- chaque apprenant a un rythme d’apprentissage qui lui est propre et qui doit être respecté ;
- l’apprenant a besoin d’être guidé pour éviter les renforcements négatifs qui pourraient le décourager.
Skinner prévoyait en revanche et contrairement au principe de l’adaptive learning, une progression parfaitement linéaire dans les unités d’apprentissage. C’est ainsi qu’a émergé l’apprentissage programmé dont les ressorts ont été affinés par la suite, notamment par un autre psychologue comportementaliste américain, Nicholas Crowder dans les années 60. A la linéarité de Skinner, Crowder préfère une ramification des savoirs organisés en parcours adaptables à la progression de l’apprenant. Pour la petite histoire, Crowder variait déjà les formats de contenus en mêlant textes, vidéos et audio.
En ce temps-là, en l’absence d’analyse fine des données, l’ancêtre de l’adaptive learning se résumait à automatiser certaines tâches de correction et de déblocage du grain de savoir suivant.
Aujourd’hui, la richesse d’analyse que permettent le big data et l’intelligence artificielle ouvre la voie à une construction quasiment à la volée d’un parcours sur-mesure tenant compte des informations fournies par l’apprenant et de celles constatées via l’interface.
3.
L’APPRENANT sous son meilleur PROFIL
« Face à un enseignement identique, deux sujets n’apprennent pas la même chose. Ils ne disposent pas des mêmes acquis et utilisent des stratégies différentes pour apprendre. L’imagerie a confirmé que nous utilisons des chemins cognitifs différents pour parvenir au même résultat. » Voilà résumé, dans l’ouvrage Neurolearning – Les neurosciences au service de la formation, co-écrit par le Docteur Nadia Medjad, Philippe Gil et Philippe Lacroix, le challenge de la formation aujourd’hui : construire non plus un parcours de formation mais une véritable roadmap de montée en compétences pour chaque apprenant.
« De chacun selon ses moyens, à chacun selon ses besoins »
Que Karl Marx nous pardonne le détournement de sa célèbre maxime, mais difficile de trouver plus appropriée pour fixer l’objectif de l’adaptive learning. Chaque apprenant dispose d’un rythme d’apprentissage propre, de préférences dans les modes d’acquisition des savoirs, d’aptitudes et de motivations personnelles.

On peut ajouter le style d’apprentissage, à condition d’« éVAKuer » tout de suite le mythe du visuel, auditif ou kinesthésique (VAK) qui ne reflète que de simples préférences, fruit le plus souvent d’habitudes de travail. Qu’on se le dise, nous sommes tous des visuels dans l’âme, pour lesquels une image vaut mille mots.
De nombreux chercheurs ont défini des styles d’apprentissage. Parmi les plus célèbres, Kolb a définit des cycles d’apprentissage regroupant 4 phases. Parmi ces 4 phases, l’apprenant présente en général une préférence pour 2 des phases. Il a ainsi identifié 4 profils d’apprenant selon leur appétence pour telles ou telles phases. Pour chacun de ces 4 profils, il est ainsi préférable de présenter des modalités d’apprentissage plus ou moins axées sur l’expérimentation ou au contraire sur la réflexion et l’apport théorique… Pour en savoir plus : https://digital-learning-academy.com/styles-dapprentissage-la-typologie-de-kolb/
Pour ajuster au mieux le parcours de formation à l’apprenant, il est ainsi nécessaire de le connaître, de recueillir diverses données personnelles. On peut classer ces données en deux catégories selon que l’on soit en présence de données fournies ou de données constatées :
Pour ajuster au mieux le parcours de formation à l’apprenant, il est ainsi nécessaire de le connaître, de recueillir diverses données personnelles. On peut classer ces données en deux catégories selon que l’on soit en présence de données fournies ou de données constatées :
- les données fournies sont celles que l’apprenant va volontairement et consciemment soumettre : son âge, ses expériences, son parcours professionnel ou son niveau d’étude, son objectif personnel de formation peut-être, etc… ;
- les données constatées sont celles révéler par sa navigation, son temps de connexion par support et par format de ressource pédagogique, ses annotations en ligne sur les supports, ses hésitations mesurées par le différentiel entre le temps moyen constaté qu’il met à répondre aux questions et le temps réel enregistré sur une question précise, ses erreurs et les résultats de ses évaluations. Son comportement va ainsi générer des données sans même qu’il ne s’en rende compte.
Cette deuxième série d’informations (partie immergée de l’iceberg du profil de l’apprenant), que l’on peut assimiler à des traces, se constitue au fur et à mesure de son avancement dans la formation. Elle est fondamentale dans l’adaptation de la formation. De la qualité des learning analytics va découler la richesse d’utilisation de cette précieuse source de données. Voici donc qualifiés les « moyens » de l’apprenant, première proposition de la célèbre maxime marxiste. En découleront ses « besoins » de formation couverts par la conception et l’ingénierie pédagogique déployée, l’ergonomie de l’interface et l’accompagnement tutoral dédié.
Cette récolte d’information va définir un profil d’apprenant classifiable dans une cohorte présentant un profil similaire. Cette catégorisation guidera ainsi le pédagogue dans la constitution de parcours différenciés contenant des contenus granularisés multi-formats.
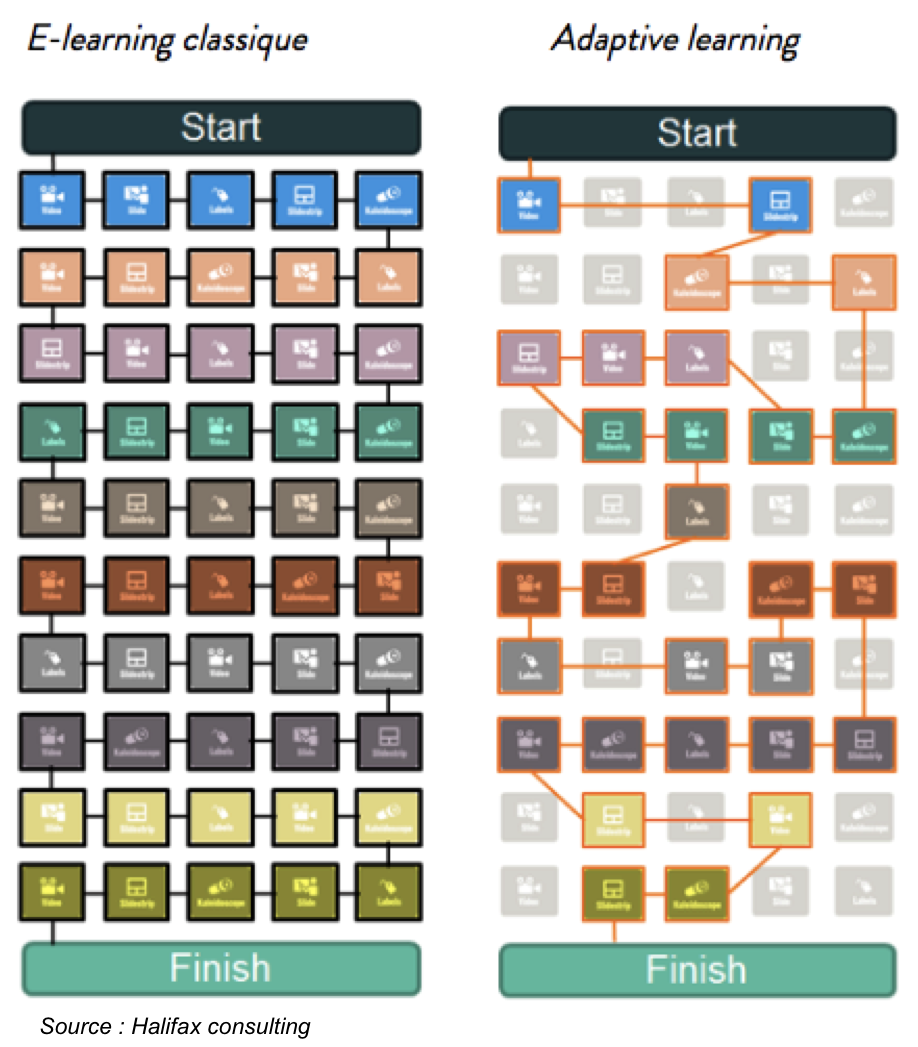
4.
Pour un PARCOURS ADAPTÉ, séparer le BON GRAIN de l’ivraie
Un mauvais contenu avec le meilleur algorithme du monde ne permettra pas de satisfaire à un objectif d’apprentissage adapté à même de délivrer à l’apprenant le contenu adéquat au meilleur moment.
Scénarisez le parcours
Toutes les ressources pédagogiques sont hiérarchisées. Elles forment ainsi un parcours d’apprentissage cohérent (certaines notions ne peuvent pas être abordées sans qu’une autre ne soit maîtrisée en prérequis, par exemple). Les activités s’enchaînent selon un degré de difficulté croissant.
Cette démarche ne signifie pas que le parcours doit être linéaire. L’algorithme permet à l’apprenant, selon ses résultats, ses préférences et son rythme, de débloquer certains contenus sans même avoir suivi les prérequis. Il est libre de visionner uniquement les formats qui lui conviennent (particulièrement dans le cas de handicaps sensoriels) : contenus audio par exemple, pour une personne malvoyante.
Ganularisez les contenus
Pour être agencé de façon pertinente dans un parcours adaptable en fonction de la progression, des difficultés mais aussi des appétences et du rythme de l’apprenant, le contenu doit respecter quelques critères.
Un mot d’ordre à la conception : granularisez ! Le contenu doit être découpé en grains pédagogiques (un grain représente la plus petite unité de savoir faisant sens) autonomes de courte durée. Ils pourront être agrégés de différentes façons, dans une succession d’activités pédagogiques adaptées à la situation d’apprentissage, au profil de l’apprenant et in fine à l’objectif pédagogique.
Corollaire de la granularisation, la qualification : l’ajout de métadonnées sur chacun des grains pédagogiques est indispensable. A minima les mots clé d’indexation, la date de création, l’objectif pédagogique, le format de la ressources (texte, vidéos…).
Plus vos métadonnées seront riches, plus la modularité de votre offre sera importante. Cette étape, qui peut sembler chronophage au départ, doit être intégrée dans le planning de production.
Lors de la conception de la formation, reliez chaque savoir ou savoir-faire à un bloc de compétences défini en amont. S’il vous est arrivé de plonger dans un référentiel de l’Éducation nationale (récent de préférence), vous aurez constaté que chaque savoir est associé à une compétence et à un mode d’évaluation.
Définissez, en outre, pour chaque grain de contenu, le grain prérequis et le grain subséquent. N’hésitez pas à formaliser cette arborescence de contenus dans un arbre de connaissances ou via une carte conceptuelle.
Votre contenu doit être structuré en XML ou intégré en base de données afin d’être facilement identifié comme ressource mobilisable par le logiciel qui va « jouer » votre parcours. Cela facilitera également grandement les opérations d’actualisation du contenu.
Et pour finir, multipliez les formats des grains pédagogiques (textes, vidéos, serious games, audio) et les méthodes pédagogiques : méthode inductive en partant d’une série de questions, méthode expositive pour les savoirs académiques, mises en situation, remédiation, travail collaboratif… sans oublier les évaluations, indispensables à l’apprenant pour mesurer sa progression et à l’algorithme pour personnaliser le parcours.

5.
De l’adaptive learning
à l’ADAPTIVE TEACHING
L’adaptive learning va-t-il enterrer le formateur ? La réponse est bien évidemment : non ! Le formateur a tout à gagner à tirer les enseignements des données glanées via l’interface s’agissant notamment des learning analytics : le big data comme support d’objectivation de ses choix pédagogiques.
Le formateur/tuteur va ainsi pouvoir se concentrer sur des missions d’accompagnement de l’apprenant en identifiant rapidement les points de blocage, en modifiant, au besoin, certaines ressources mal comprises de la communauté des apprenants, en animant la communauté d’apprentissage, en apportant à travers ses feedback, une dimension relationnelle et sociale que l’intelligence artificielle ne peut pas encore remplacer. Ils peuvent également se concentrer sur les sessions présentielles dans le cadre de parcours en blended learning.
6.
L’adaptive learning
plus fort que les MOOCs ?
L’adaptive learning reste encore peu développé, notamment en France. Aux États-Unis, environ 5% des universités ont mis en place des parcours en adaptive learning. On dispose donc pour l’heure de peu de recul pour mesurer l’efficience de la démarche.
Toutefois, une étude de 2015 réalisée par le cabinet conseil Tyton Partners montre que l’adaptive learning permettrait d’augmenter d’environ 25 % le temps passé par les étudiants sur les modules en ligne. L’université de l’Arizona, utilisatrice de la solution Knewton (société américaine spécialisée dans l’adaptive learning) pour ses modules de mathématiques a constaté une croissance de 18 % de la part des étudiants ayant validé au moins un module. Le taux d’abandon sur ce même échantillon d’étudiants aurait chuté de 47 %.
Enfin, le rapport de Tyton Partners met en évidence un impact positif dans l’enseignement supérieur évalué à 66 % pour l’adaptive learning, contre 42 % pour les MOOCs.
L’intégralité du rapport (en anglais) ici : https://tytonpartners.com/tyton-wp/wp-content/uploads/2015/01/Learning-to-Adapt_Case-for-Accelerating-AL-in-Higher-Ed.pdf
