17 mai 2017. Il est 19H00. Sundar Pichai monte sur scène. C’est pour le PDG de Google, l’occasion de rappeler en ouverture de la grand messe annuelle de Google, la bascule de sa stratégie du « mobile-first » vers l’« AI-first. »
« AI first », comprenez primauté à l’Intelligence Artificielle (IA en français). Google n’échappe naturellement pas à la tendance actuelle des investissements massifs dans ce vaste domaine de recherche.
Depuis 2011, Google, Samsung, IBM, Twitter, Intel, Apple, Salesforce, pour ne citer qu’eux, rachètent des startups spécialisées dans l’IA.
Le sujet inonde la toile et la presse depuis plusieurs mois et pourtant il n’est pas neuf. Née dans les années 50, l’intelligence artificielle a connu des avancées diverses avec même une période de quasi mise en sommeil avant l’explosion des capacités de mémoire des ordinateurs et l’arrivée d’Internet. Aujourd’hui, les perspectives offertes par l’IA sont telles qu’elles pourraient révolutionner nos modes de vie : voiture autonome, médecine, art, relation client, assistance aux personnes âgées… L’enseignement et la formation avec, par exemple, l’adaptive learning et l’accompagnement de l’apprenant à distance commence déjà à en tirer des bénéfices pédagogiques.
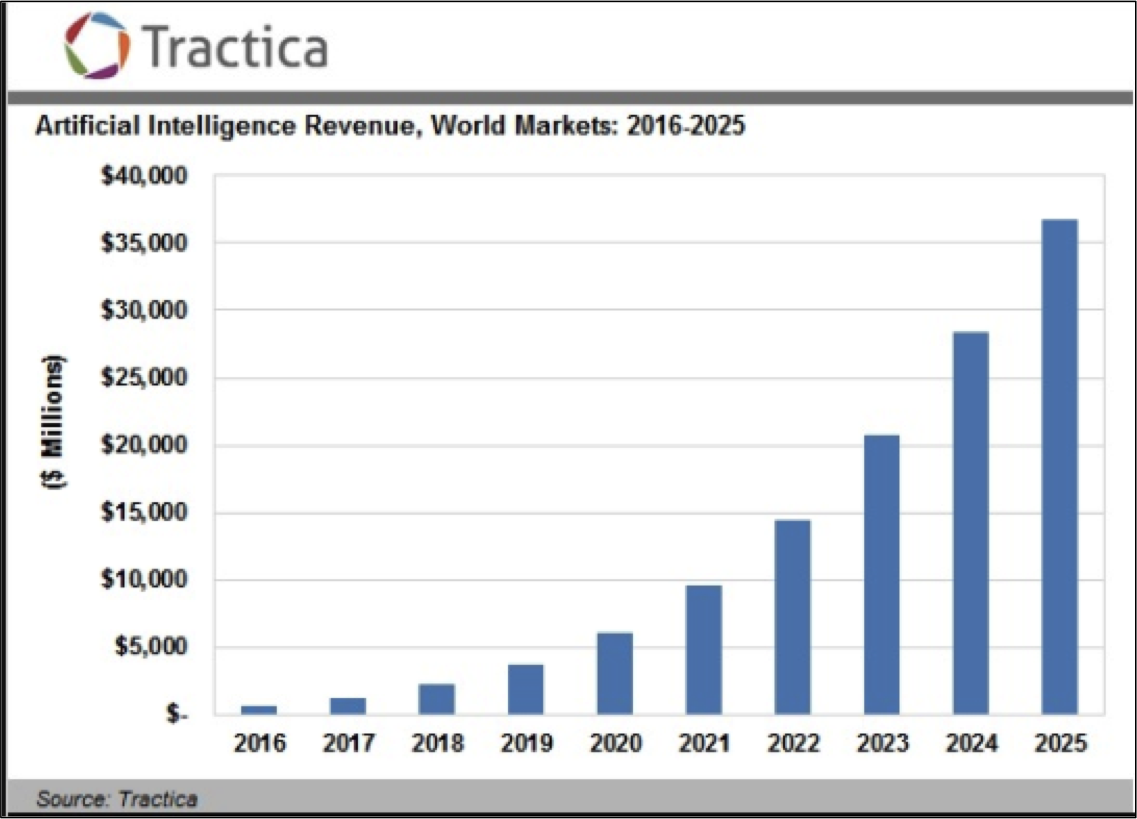
D’un point de vue économique, les revenus générés par l’IA devraient croître de façon exponentielle dans la décennie qui vient.
Parmi les axes de recherche les plus investis actuellement : le machine learning (apprentissage automatique), pan spécifique de l’IA. Et dans le champ du machine learning, émerge, grâce au big data et à la puissance de calcul des ordinateurs, le deep learning (apprentissage profond via des réseaux de neurones).
Avant d’imaginer comment machine learning et deep learning vont impacter la formation de demain, commençons par décrypter comment la machine apprend par elle-même. Alors pour une fois, c’est à la formation de la machine que nous donnerons la primauté.
1.
IA, Machine Learning et Deep Learning :
les POUPÉES RUSSES
L’IA est une discipline scientifique extrêmement vaste. L’appellation Intelligence artificielle est apparue en 1956 lors de la conférence de Dartmouth, sous l’impulsion de deux chercheurs américains, Marvin Minsky et John McCarthy. Minsky donne alors de l’IA une première définition devenue aujourd’hui réductrice : « L’intelligence artificielle est la science qui consiste à faire faire à des machines ce que l’homme fait moyennant une certaine intelligence ».
60 ans plus tard, des pans entiers de l’IA, comme le langage naturel, le sens commun ou la robotique notamment ne se retrouvent pas dans cette première définition. Et encore aujourd’hui les chercheurs ne parviennent pas à s’accorder sur une définition suffisamment large pour englober tous ses champs expérimentaux.
Pour compléter la vision plurielle de l’IA, voici deux définitions plus récentes :

Puisqu’il est si difficile de définir précisément l’IA, au moins peut-on catégoriser ses champs d’intervention. De façon générale, on distingue l’IA forte de l’IA faible.
- L’IA forte correspond à un programme capable de reproduire un comportement intelligent, autrement dit d’avoir une conscience de ses propres actions en éprouvant des « sentiments » (même si ce terme ne peut recouvrer ici toute la subtilité des sentiments humains) et une compréhension de ses raisonnements.
- L’IA faible, en revanche, consiste en une simple simulation de comportements sans aucune prise de conscience de ses actions.
Les années 90 ont vu émerger des systèmes d’IA forte avec notamment la mise au point de programmes de machine learning, basés sur des algorithmes complexes et des réseaux neuronaux. Au sein de ces programmes de machine learning, on distingue encore deux sous catégories : une première où l’homme guide la machine en indiquant le résultat escompté et une seconde où l’homme fournit uniquement des données et laisse la machine en déduire ses propres classifications pour leur donner un sens. Cette seconde subdivision est qualifiée de deep learning.
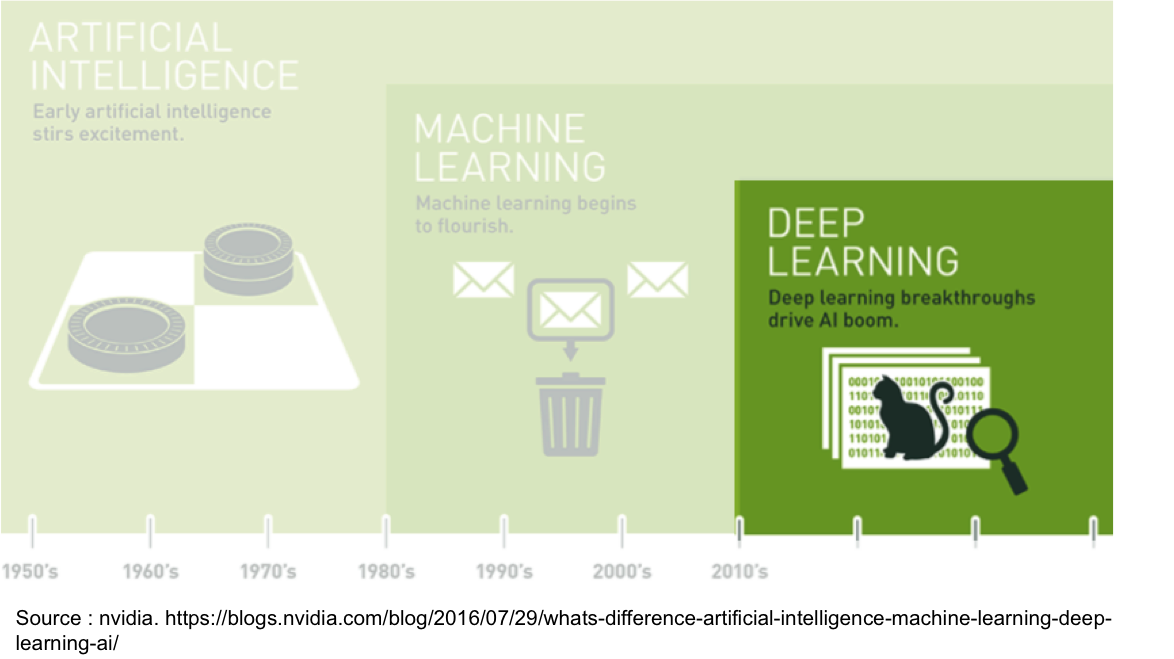
Il s’agit donc bien d’un système de poupées russes : l’IA constitue le domaine le plus large (qui n’implique pas nécessairement un apprentissage de la machine), qui comprend le machine learning (qui en revanche est bien basé sur l’apprentissage de la machine), qui lui-même comprend le deep learning (pour lequel l’apprentissage n’est pas guidé par l’homme).
Résumé en image :
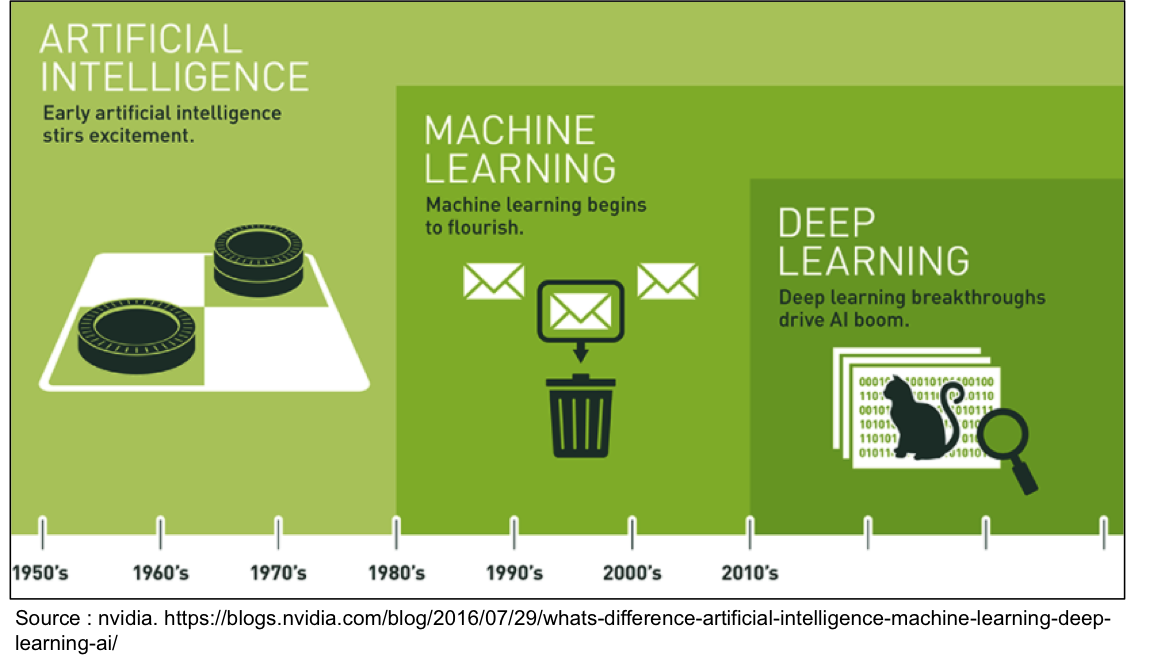
Vous constaterez sur l’image que chaque catégorie est illustrée par ce qui représente l’exemple le plus courant du fonctionnement de chacune :
- la performance pour l’IA en général, avec des machines capables de battre des champions (Deep Blue d’IBM qui bat Garry Kasparov aux échecs en 1997, par exemple) ;
- la vision analytique du machine learning, avec des programmes notamment capables de détecter quels mails ont toutes les chances de constituer des spams ;
- la résolution de problèmes avec le deep learning et la possibilité par exemple de reconnaissance d’images.Concrètement, comment un programme peut il savoir qu’il y a un chat sur l’image alors qu’aucun humain ne le lui a indiqué explicitement ? Plongée au cœur des réseaux de neurones…
2.
Machine Learning : quand l’EXPÉRIENCE remplace le CODE
Le machine learning est un système algorithmique d’apprentissage automatique de la machine, par l’entraînement. Les algorithmes reposent sur des réseaux de neurones artificiels (encore appelés réseaux de neurones formels) comportant une ou plusieurs couches successives (maillage des neurones) qui tentent de reproduire les connexions des neurones et synapses d’un cerveau humain.
Il se divise en deux grandes familles : l’apprentissage supervisé et l’apprentissage non supervisé.
A noter qu’il existe une famille intermédiaire, appelée apprentissage par renforcement. Elle est notamment appliquée en robotique pour introduire, dans les choix de la machine, une notion de récompense : le robot qui réussit à monter une marche sans tomber reçoit une information symbolisant une récompense positive. Ca ne vous rappelle rien ? Le conditionnement opérant de Skinner appliqué à la machine.
Apprentissage supervisé : quand l’homme définit le résultat escompté
Il s’agit d’un système de classification, guidé par l’homme. La machine reçoit un certain nombre d’exemples (ces exemples constituent les données d’entrées ou inputs en anglais). A chaque exemple est appliquée une étiquette (ou un label), indiquant à la machine le résultat espéré à partir de chaque exemple (ce sont les données de sortie ou outputs en anglais).
A partir des données d’entrée et des données de sortie, l’algorithme va devoir identifier une règle (en somme trouver un chemin) pour relier données d’entrée et données de sortie.
Si l’on reprend l’image de catégorisation de l’IA, illustrée par une classification des mails pour représenter le machine learning, comment l’algorithme va-t-il procéder ?
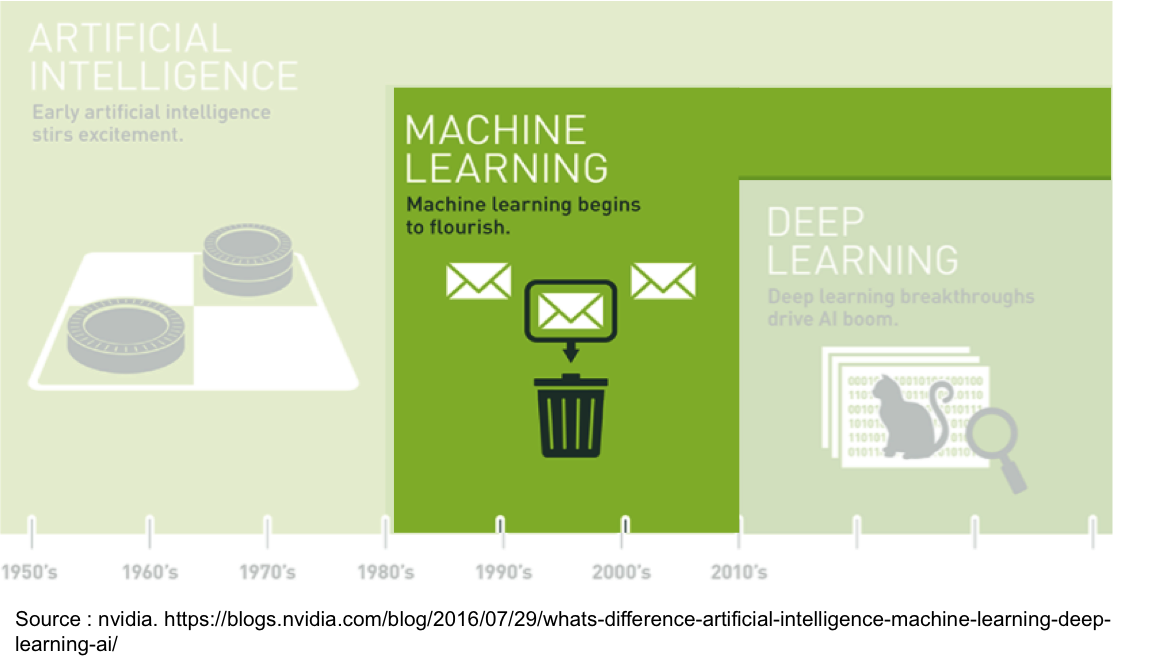
On définit deux catégories : l’e-mail valide et le spam. La machine reçoit de nombreux exemples d’e-mail étiquetés (ou labellisés) par l’homme, avec le résultat attendu : 0 pour spam et 1 pour e-mail valide. Charge alors à l’algorithme de définir la règle qui permet de classer chaque mail dans l’une des deux catégories et de l’appliquer à chaque nouveau mail reçu par l’utilisateur.
Apprentissage non supervisé : bienvenue dans le deep learning
Imaginez que vous deviez décrire comment votre cerveau procède pour décortiquer une image et identifier exactement ce qu’elle contient… Vous n’y parviendriez pas. Nous passons notre enfance, guidé par notre entourage, pour apprendre à décrypter le monde qui nous entoure avec des représentations admises par tous. Et cet apprentissage nous le réalisons essentiellement par l’expérience et non par l’apprentissage de règles formelles et théoriques de ce qui constitue chaque chose que nous voyons ou chaque situation que nous rencontrons.
Dans le cas de tâches très complexes de ce type, on utilise donc d’autres méthodes d’apprentissage que les processus supervisés : il s’agit des processus non supervisés. Le deep learning procède d’un apprentissage non supervisé.
Dans ce processus, la machine reçoit de grandes quantités d’exemples en données d’entrées (ou inputs). Mais à la différence de l’apprentissage supervisé, on ne qualifiera pas, pour elle, les données d’entrées avec une étiquette (ou label). La machine va devoir compartimenter et classifier les données par elle-même. On parle ici souvent de « clusters ». On qualifie cette démarche d’apprentissage profond (deep en anglais) parce que la machine va devoir procéder en plusieurs étapes successives pour atteindre un résultat. Ce résultat sera son propre résultat.
Si l’on reprend encore une fois l’image de catégorisation de l’IA, illustrée par la reconnaissance de l’image d’un chat pour représenter le deep learning, comment l’algorithme va-t-il procéder ?
Comment l’algorithme peut-il en analysant une image, savoir qu’un chat y est présent ? On aura préalablement nourrit la machine de milliers voire de centaines de milliers d’images de chats. La machine analyse alors chaque image par étapes successives : chaque couche de neurones va analyser de plus en plus finement l’image. In fine l’algorithme va définir lui même les règles qui font qu’un chat est un chat et non un chien.
Les réseaux de neurones ont donc plusieurs couches successives qui conduisent (le plus souvent) à une identification pertinente. Facebook a ainsi créé une application de reconnaissance de visages baptisée « Deepface », qui comporte des réseaux de neurones à 9 couches.
Pour en savoir plus sur les stratégies d’utilisation du deep learning, un peu plus de 4 minutes d’explication en vidéo par Emmanuel Mogenet, directeur de Google Research Europe, réalisée pour Sciences et avenir…
Résumé en image…
De façon très schématique et simplifiée, on peut comparer les deux modèles (supervisé et non-supervisé) de la façon suivante :

3.
Machine learning et deep learning :
quelles applications en FORMATION ?
Comment l’apprentissage automatique de la machine va-t-il renforcer l’apprentissage humain ?
De nombreux secteurs comme la médecine, la finance ou l’expérience client ont d’ores et déjà progressé grâce au machine learning.

En matière d’éducation et de formation, l’intelligence artificielle en général et le machine learning en particulier permettent de répondre à la question de la modélisation des apprenants. En analysant les données de milliers d’apprenants, leur comportement face à un parcours, il est possible à la machine de définir un profil et des caractéristiques d’apprentissage plus personnalisées. Le formateur/tuteur sera également guidé dans sa démarche d’accompagnement de l’apprenant par une meilleure connaissance des points forts et des axes de progrès de ce dernier.
En fonction du profil de l’apprenant, il est ainsi possible de lui recommander certaines ressources complémentaires, de lui adresser des éléments de prérequis, d’agencer son parcours en maximisant les formats (vidéos ou textes…) qui lui conviennent le mieux. En résumé, mettre en place une véritable démarche d’#adaptive learning.
Pour remettre en perspective le fonctionnement des algorithmes de machine learning, les données d’entrées sont constituées par les traces d’activité de l’apprenant et les informations fournies de façon volontaire sur son profil ainsi que par l’ensemble des données des cohortes d’apprenants ayant suivi le parcours. Certains algorithmes tiennent également compte des interactions sociales des apprenants entre eux pour adapter les séquences de formation.
Les #chatbots constituent également une plus-value dans le parcours apprenant. Leur fonctionnement à base de machine learning leur permet d’orienter l’apprenant dans ses démarches, d’animer une communauté sur des questions simples, de séquencer le parcours et de décharger le formateur de tâches à faible valeur ajoutée pédagogique.
Mais la plus grande avancée des systèmes d’IA et du deep learning est sans doute la prédiction. En fonction d’événements aléatoires ou d’enchaînement d’actions, le système peut prévoir une issue (quelle soit positive ou négative) et alerter avant même que la situation finale ne se réalise. Ces modèles sont d’ores et déjà testés en médecine pour anticiper l’évolution des affections par exemple.
En formation, cela pourrait signifier qu’une baisse de motivation, voire un abandon, anticipés par l’algorithme notant une absence de connexion ou des échanges à connotation négative dans la communauté d’apprenants (d’où la nécessité de combiner les algorithmes avec des fonctions de reconnaissance et d’interprétation du langage naturel), pourrait être prise en compte. Elle pourrait alors être corrigée par la création d’événements pédagogiques destinés à remotiver l’apprenant (classes virtuelles, workshop…), à recréer du lien social avec ses pairs, à ajuster le niveau des ressources s’il est trop élevé ou trop faible.
On le voit, le champ des possibles ne cesse de s’élargir, en formation comme dans l’ensemble des domaines de la vie courante, mais aussi moins courante. Terminons sur un peu de rêve et de magie…
4.
Laisser RÊVER les algorithmes !
Ce n’est sans doute pas le domaine auquel on pense immédiatement lorsque l’on évoque les possibilités des algorithmes d’IA, et pourtant… L’art constitue un véritable pan de recherche ou tout au moins d’expérimentations.
Qu’il s’agisse d’imitation ou d’œuvres totalement originales, des essais ont récemment fait l’objet d’une large médiatisation.
The next Rembrandt
400 ans après la mort de Rembrandt des chercheurs ont créé, grâce à l’intelligence artificielle et à une imprimante 3D, un nouveau tableau reprenant toutes les caractéristiques des toiles du maître hollandais. Les chercheurs ont ainsi fait analyser 300 tableaux de Rembrandt par l’algorithme, qui, au terme de 500 heures de calcul, a réussi à faire naître un tableau plus vrai que nature.
Le résultat du projet « The next Rembrandt » en image :

Rembrandt réincarné dans un algorithme !
Si vous voulez connaître (en 8 minutes) toutes les interrogations physiques et métaphysiques auxquelles s’est confrontée l’équipe qui a mené le projet, Arte y a consacré une édition de son magazine « FutureMag » dédié à l’innovation :
Deep Dream
Depuis 2 ans, l’un des algorithmes de Google rêve en direct sur le net. Comprenez, il bug en direct, créant des œuvres pour le moins insolites. Le phénomène s’est même trouvé un nom : « Inceptionnisme » en référence au film de Martin Scorsese, transformant, par ce baptême, l’erreur en pseudo-courant artistique. En effet, l’algorithme, entraîné à reconnaître des formes, en identifie partout, même là où il n’y en a pas.
Si l’intérêt esthétique est discutable, l’expérience est amusante et permet de mieux appréhender le fonctionnement de la reconnaissance d’images. Baptisé Deep Dream, le réseau de neurones artificiels est programmé pour identifier, sur les photos soumises par les internautes, les formes qu’il repère (animaux, bâtiments, visages…) et qui n’existent que dans son « imagination ».
Fantasmagorie du 0 et du 1 :

Envie de faire rêver l’algorithme de Google ? C’est ici : https://deepdreamgenerator.com/
